MapReduce的Reduce Size Join
本文共 493 字,大约阅读时间需要 1 分钟。
mapper side join
这个没仔细讲,但是是在每个Mapper里来做的。
reduce side join
老师讲的非常清楚了,比如说CustomerMapper和OrderMapper,我都是处理出一个key-value值,这个key就是两个表都有的字段比如说Customer_Id。当然,order这边可能一个Customer会有多个订单,所以是多个订单记录组成的value。
现在就非常清晰了:
CustomerMapper的key是Customer_Id
CustomerMapper的value是整条记录(我们给他加个001, 来表示一下它是Customer的数据)
OrderMapper的key也是Customer_Id
OrderMapper的value是整条记录(我们给他加个002, 来表示一下它是Order的数据,注意一下他是可能一个客户有多个订单)

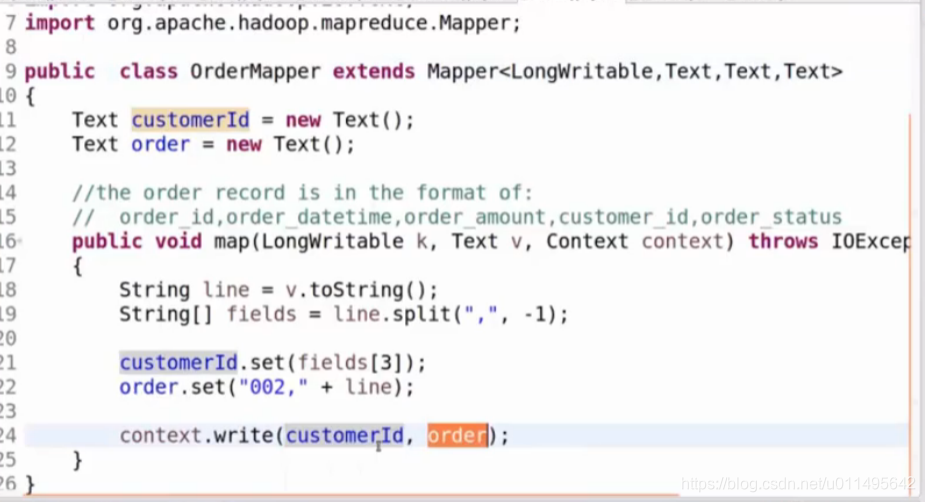
然后这两对key-value,shuffle到Reducer。
Reducer接收这两组数据,001的和002的数据,key相同的直接用 +合并即可。
order这里的处理呢,是因为一个客户有多个订单。

转载地址:http://uzvws.baihongyu.com/
你可能感兴趣的文章
Docker基础-14-Dockerfile实战练习2
查看>>
Docker基础-15-容器操作
查看>>
Docker基础-16-网络-Linux网络命名空间
查看>>
Docker基础-17-网络-两个容器为什么能通信
查看>>
Docker基础-18-网络-两个网络命名空间网络通信配置过程
查看>>
Docker基础-19-网络-bridge模式和docker0详解
查看>>
Docker基础-20-网络-容器link关系和新建bridge网络
查看>>
Docker基础-21-网络-none和host网络
查看>>
Docker基础-22-volume-数据持久化之data volume
查看>>
Docker基础-23-数据-数据持久化之Bind Mouting
查看>>
Java数据结构和算法-1-数组-自定义封装一个数组操作类(1)
查看>>
Java数据结构和算法-2-数组-自定义封装一个数组操作类(2)
查看>>
Java数据结构和算法-3-数组-简单排序:冒泡排序/选择排序/插入排序
查看>>
Java数据结构和算法-4-栈和队列-封装一个自定义栈和队列类并提供相关类方法
查看>>
Java数据结构和算法-5-单链表方法
查看>>
Jenkins高级篇之Pipeline技巧篇-1-小白搭建Pipeline项目开发环境
查看>>
Jenkins高级篇之Pipeline技巧篇-2-如何处理多个参数化变量
查看>>
Jenkins高级篇之Pipeline技巧篇-3-JSON文件处理多个参数进一步优化
查看>>
Jenkins高级篇之Pipeline技巧篇-4-根据参数传入条件控制执行不同stage
查看>>
Jenkins高级篇之Pipeline技巧篇-5-pipeline中如何代码串联多个job的执行
查看>>